
1. Guide: Installing and Using Local Stable Diffusion with Graphical Interface on Windows
1. Guide: Installing and Using Local Stable Diffusion with Graphical Interface on Windows
Quick Links
- What Is Stable Diffusion?
- What Do You Need to Run This Version of Stable Diffusion?
- How to Install Stable Diffusion with a GUI
- How to Generate Images Using Stable Diffusion with AUTOMATIC1111’s WebUI
- How to Mask Images You Create to Inpaint
- How to Use Stable Diffusion with ComfyUI
- How to Fix the “CUDA Out Of Memory” Error in AUTOMATIC1111’s WebUI
You can install Stable Diffusion locally on your PC , but the typical process involves a lot of work with the command line to install and use. Fortunately for us, the Stable Diffusion community has solved that problem. Here’s how to install a version of Stable Diffusion that runs locally with a graphical user interface!
What Is Stable Diffusion?
Stable Diffusion is an AI model that can generate images from text prompts, or modify existing images with a text prompt, much like MidJourney or DALL-E 2 . It was first released in August 2022 by Stability.ai. It understands thousands of different words and can be used to create almost any image your imagination can conjure up in almost any style.
There are two critical differences that set Stable Diffusion apart from most of the other popular AI art generators, though:
- It can be run locally on your PC
- It is an open-source project
Related: Stable Diffusion Brings Local AI Art Generation to Your PC
The last point is really the important issue here. Traditionally, Stable Diffusion is installed and run via a command-line interface . It works, but it can be clunky, unintuitive, and it is a significant barrier to entry for people that would otherwise be interested. But, since it is an open source project, the community quickly created multiple user interfaces for it and began adding their own augmentations, including optimizations to minimize video ram (VRAM ) usage and build in upscaling and masking.
What Do You Need to Run This Version of Stable Diffusion?
We’re going to cover two different forks (offshoots) of Stable Diffusion of the main repository (repo) created and maintained by Stability.ai . They both have a graphical user interface (GUI) — making them easier to use than the regular Stable Diffusion, which only has a command-line interface — and an installer that’ll handle most of the setup automatically. They both provide the same basic functionality, but the user experience is quite different. AUTOMATIC1111’s WebUI is very intuitive, and the easiest to learn and use, but ComfyUI offers an interesting and powerful node-based user interface that will appeal to power users and anyone that wants to chain multiple models together.
As always, be careful with third-party forks of software that you find on GitHub. We’ve been using these for a while now with no issues, and so have thousands of others, so we’re inclined to say it is safe. Fortunately, the code and changes here are small compared to some forks of open-source projects.
These forks also contains various optimizations that should allow it to run on PCs with less RAM, built-in upscaling and facial capabilities using GFPGAN, ESRGAN, RealESRGAN, and CodeFormer, and masking. Masking is a huge deal — it allows you to selectively apply the AI image generation to certain parts of the image without distorting other parts, a process typically called inpainting.
- A minimum of 10 gigabytes free on your hard drive
- You can reuse the same Python environment and checkpoints to save on space if you want to use both ComfyUI and AUTOMATIC1111’s WebUI.
- You may also simply install them separately, which is much easier.
- An NVIDIA GPU with 6 GB of RAM (though you might be able to make 4 GB work)
- SDXL will require even more RAM to generate larger images.
- You can make AMD GPUs work, but they require tinkering
- A PC running Windows 11, Windows 10, Windows 8.1, or Windows 8
- One of:
- The WebUI GitHub Repo by AUTOMATIC1111
- ComfyUI
- Python 3.10.6 (Use this version to ensure there aren’t compatibility problems)
- The Stable Diffusion Official Checkpoints (Keep an eye out for new versions!)
- Any additional models you might want. You can use as many or few as you want.
How to Install Stable Diffusion with a GUI
The installation process has been streamlined significantly, but there are still a few steps you need to do manually before the installer can be used.
Install Python First
The first thing you should do is install the version of Python, 3.10.6 , recommended by the author of the repo. Head to that link, scroll towards the bottom of the page, and click “Windows Installer (64-Bit) .”
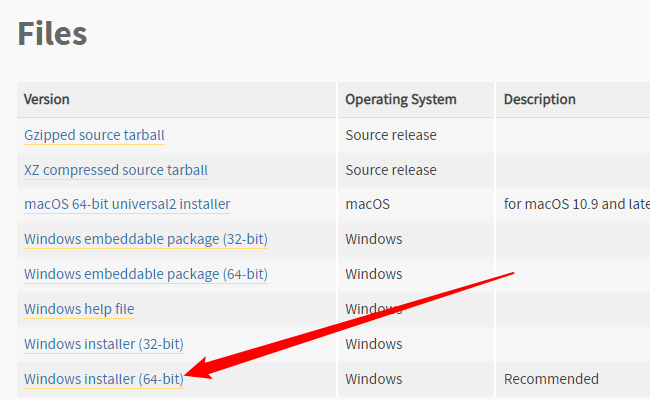
Click the executable you downloaded and go through the prompts. If you already have Python installed (and you most certainly do), just click “Upgrade.” Otherwise follow along with the recommended prompts.
Make certain that you add Python 3.10.6 to the PATH if you get an option for that.
Install Git and Download the GitHub Repo
You need to download and install Git on Windows before the Stable Diffusion installer can be run. Just download the 64-bit Git executable , run it, and use the recommended settings unless you have something specific in mind.
Related: How to Install Git on Windows
Next, you need to download the files from the GitHub for either AUTOMATIC1111’s WebUI , ComfyUI , or both.
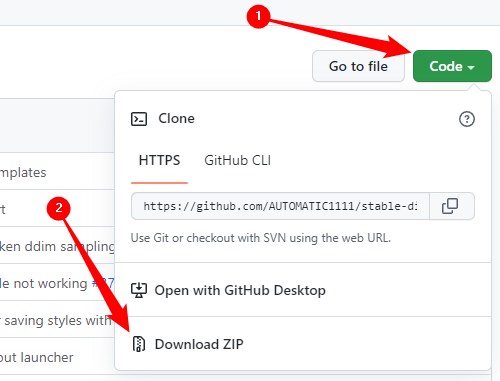
If you’re going with AUTOMATIC1111’s WebUI, click the green “Code” button, then click “Download ZIP” at the bottom of the menu.
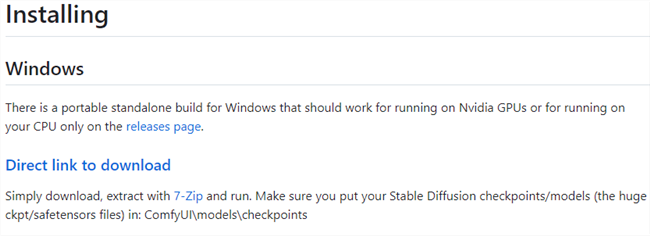
If you want to take ComfyUI out for a spin, scroll down to the “Installing “ section, and click “Direct Link to Download.”
Open up the archive file in File Explorer or your preferred file archiving program , and then extract the contents anywhere you want. Just keep in mind that folder is where you’ll need to go to run Stable Diffusion. This example extracted them to the C:\ directory, but that isn’t essential.
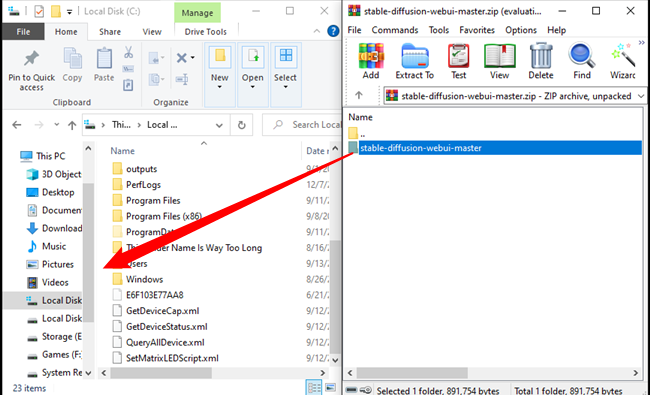
Make sure you don’t accidentally drag “stable-diffusion-webui-master” or “ComfyUI_windows_portable” onto another folder rather than empty space — if you do, it’ll drop into that folder, not the parent folder you intended.
Download All The Checkpoints
There are a few checkpoints you require for this to work. The first and most important are the Stable Diffusion Checkpoints . At the time of writing, AUTOMATIC1111’s WebUI will automatically fetch the version 1.5 checkpoints for you. If you want to use the SDXL checkpoints, you’ll need to download them manually . ComfyUI doesn’t fetch the checkpoints automatically. You may want to also grab the refiner checkpoint . It isn’t strictly necessary, but it can improve the results you get from SDXL, and it is easy to flip on and off.
The checkpoints download is several gigabytes. Don’t expect it to be done instantly.
Once the checkpoints are downloaded, you must place them in the correct folder. If you’re following what we’ve done exactly, that path will be “C:\stable-diffusion-webui\models\Stable-diffusion” for AUTOMATIC1111’s WebUI, or “C:\ComfyUI_windows_portable\ComfyUI\models\checkpoints” for ComfyUI.
Now you have options. You can add additional models (like ESRGAN, Loras , etc) that add extra functions. Some simply increase upscaling quality, whereas others are designed to give better results for specific types of images, like anime, landscape photographs, realistic portaits, specific artists, or almost anything else you can imagine. Both ComfyUI and AUTOMATIC1111’s WebUI create appropriately named folders for those additional models — just drag and drop, and you’re good.
Now you just have to run the batch file for either ComfyUI or AUTOMATIC1111’s WebUI. Open up the main AUTOMATIC1111’s WebUI folder and double click “webui-user.bat” if you want to use that interface, or open up the ComfyUI folder and click “run_nvidia_gpu.bat” to run ComfyUI.
Expect the first time you run this to take at least a few minutes. It needs to download a bunch of stuff off the Internet. If it appears to hang for an unreasonably long time at one step, just try selecting the console window and hitting the Enter key.
They’ll both look something like that.
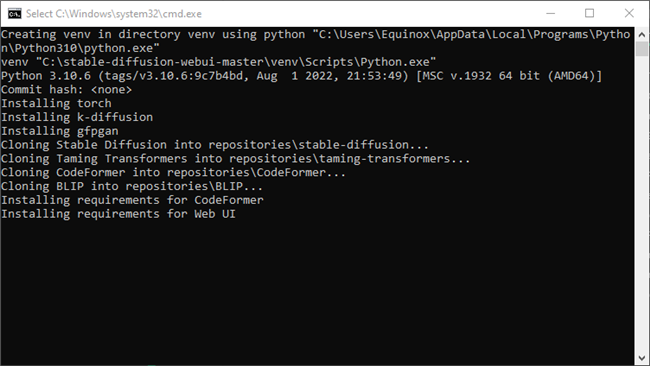
When it is done, the console will display:
Running on local URL: http://127.0.0.1 :7860 To create a public link, set share=True in launch()
Related: What Is the 127.0.0.1 IP Address, and How Do You Use It?
ComfyUI will run on the same IP address, since it is a locally hosted web interface, but it runs on the 8188 port instead of 7860.
How to Generate Images Using Stable Diffusion with AUTOMATIC1111’s WebUI
Alright, you’ve installed the WebUI variant of Stable Diffusion, and your console let you know that it is “running on local URL: http://127.0.0.1:7860 .”
What exactly does that mean, what is happening? 127.0.0.1 is the localhost address — the IP address your computer gives itself. This version of Stable Diffusion creates a server on your local PC that is accessible via its own IP address, but only if you connect through the correct port : 7860.
Open up your browser, enter “127.0.0.1:7860” or “localhost:7860” into the address bar, and hit Enter. You’ll see this on the txt2img tab:
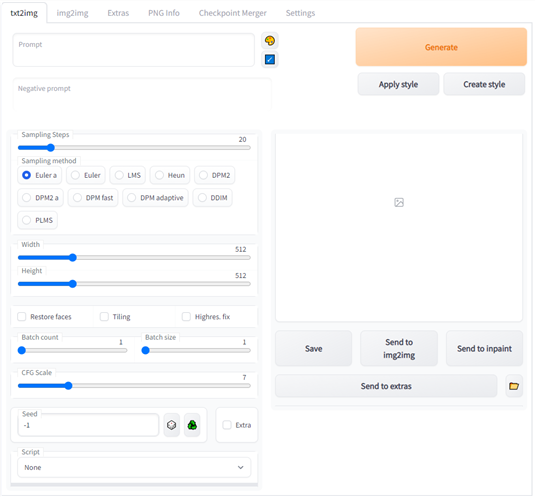
If you’ve used Stable Diffusion before, these settings will be familiar to you, but here is a brief overview of what the most important options mean:
- Prompt: The description of what you’d like to create.
- Painter’s Pallete Button: Applies a random artistic style to your prompt.
- Sampling Steps: The number of times the image will be refined before you receive an output. More is generally better, but there are diminishing returns.
- Sampling Method: The underlying math that governs how sampling is handled. You can use any of these, but euler_a and PLMS seem to be the most popular options. You can read more about PLMS in this paper.
- Restore Faces: Uses GFPGAN to try to fix uncanny or distorted faces.
- Batch Count: The number of images to be generated.
- Batch Size: The number of “batches”. Keep this at 1 unless you have an enormous amount of VRAM.
- CFG Scale: How carefully Stable Diffusion will follow the prompt you give it. Larger numbers mean it follows it very carefully, whereas lower numbers give it more creative freedom.
- Width: The width of the image you want to generate.
- Height: The width of the image you want to generate.
- Seed: The number that provides an initial input for a random-number generator. Leave it at -1 to randomly generate a new seed.
Let’s generate five images based on the prompt: “a highland cow in a magical forest, 35mm film photography, sharp” and see what we get using the Euler a sampler, 40 sampling steps, and a CFG scale of 5.
You can always hit the “Interrupt” button to stop generation if your job is taking too long.
The output window will look like this:

Your images will be different.
The bottom-left image is the one we’ll use to try out for masking a bit later. There isn’t really a reason for this specific choice other than personal preference. Grab any image that you like.

Select it, and then click “Send to Inpaint.”
How to Mask Images You Create to Inpaint
Inpainting is a fantastic feature. Normally Stable Diffusion is used to create entire images from a prompt, but inpainting allows you selectively generate (or regenerate) parts of the image. There are two critical options here: inpaint masked, inpaint not masked.
Inpaint masked will use the prompt to generate imagery within the area you highlight, whereas inpaint not masked will do the exact opposite — only the area you mask will be preserved.
We’ll cover a bit about Inpaint masked first. Drag your mouse around on the image holding left click and you’ll notice a white layer appearing over top of your image. Draw out the shape of the area you want to be replaced, and be sure to fill it in entirely. You aren’t circling a region, you’re masking in the entire region.
If you’re just adding something to an existing picture, it can be helpful to try to make the masked region line up with the approximate shape you’re trying to create. Masking a triangular shape when you want a circle, for example, is counter-productive.
Let’s take our highland cow example and give him a chef’s hat. Mask out a region in approximately the shape of a Chef’s hat, and make sure to set “Batch Size” to more than 1. You’ll probably need multiple to get an ideal(ish) result.
Additionally, you should select “Latent Noise” rather than “Fill,” “Original,” or “Latent Nothing.” It tends to produce the best results when you want to generate a completely new object in a scene.

Prompt: “a highland cow wearing a chef’s hat in a magical forest, 35mm film photography, sharp”
Mask Blur: 10
Masked Content: Latent Noise
Inpaint Area: Whole Picture
Sampling Method: Euler A
Sampling Steps: 30
CFG Scale: 5
Alright — maybe a chef’s hat isn’t the right pick for your highland cow. Your highland cow is more into the early-20th century vibes, so let’s give him a bowler hat.

Prompt: “a highland cow wearing a bowler hat in a magical forest, 35mm film photography, sharp”
Mask Blur: 10
Masked Content: Latent Noise
Inpaint Area: Whole Picture
Sampling Method: Euler A
Sampling Steps: 30
CFG Scale: 5
How positively dapper.
Of course, you can also do the exact opposite with Inpaint Not Masked. It is conceptually similar, except the regions you define are reversed. Instead of marking out the region you want to change, you mark out the regions you want to be preserved. It is often useful when you want to move a small object onto a different background.
How to Use Stable Diffusion with ComfyUI
ComfyUI is very different from AUTOMATIC1111’s WebUI, but arguably more useful if you want to really customize your results. ComfyUI runs on nodes. If you’re not familiar with how a node-based system works, here is an analogy that might be helpful.
Imagine that ComfyUI is a factory that produces an image. Within the factory there are a variety of machines that do various things to create a complete image, just like you might have multiple machines in a factory that produces cars. In the case of ComfyUI and Stable Diffusion, you have a few different “machines,” or nodes. It looks like this:
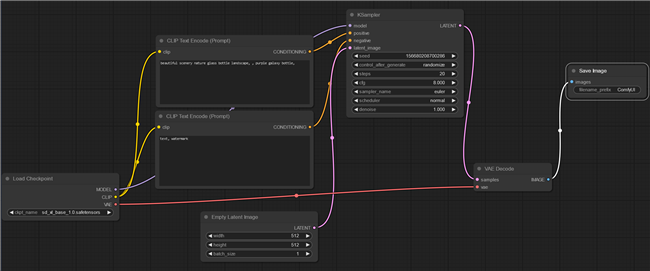
It looks worse than it really is. Here’s what each node does:
- Load Checkpoint: Loads the trained model.
- Clip Text Encode: Where you enter a prompt. There are two because we have both a positive prompt, which tells Stable Diffusion what you want, and a negative prompt, which tells it what to avoid.
- Empty Latent Image: Creates a blank (noisey) image.
- KSampler: The node that containers the sampler. The sampler is the part of the program that converts random noise into recognizeable “stuff”.
- VAE Decode: Creates the final image.
- Save Image: Writes the image to your hard drive.
Each node has various attachment points that tell you what you need to “plug in” to each point, much like conveyor belts connecting different machines in a factory. So if you wanted the prompt: “a highland cow in a magical forest, 35mm film photography, sharp” you’d enter it in the box attached to the “positive” position on the sampler node.
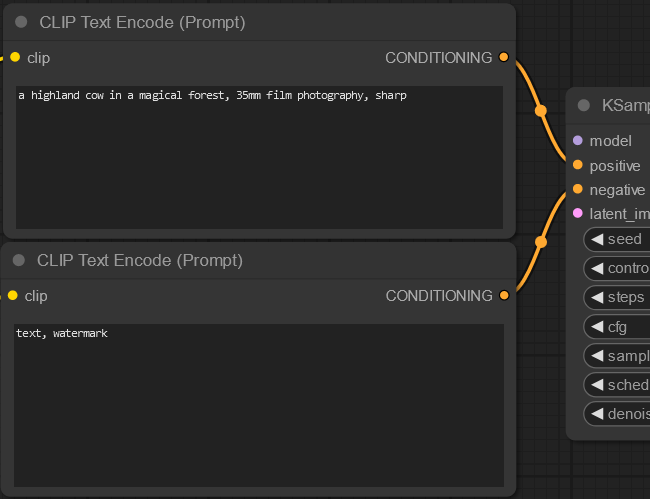
We disconnected the latent image and model nodes to clear up some clutter for the screenshot, but they must be connected for Stable Diffusion to function.
Then you need to pick the settings you want the sampler to use. You can get wildly different results here depending on what you select.
- Seed: A random number used to generate the original noise in the image.
- CFG: How strongly Stable Diffusion will adhere to the prompt. The higher the value, the more carefully Stable Diffusion will follow the prompt.
- Steps: How many times the sampler will sample the noise to generate an image.
- Sampler_name: The sampler that you use to sample the noise. These usually produce different results, so test out multiple.
- Denoise: Relevant to inpainting and img2img. Relates to how much your output image resembles your input image. The higher the value, the more dissimilar they will be.
Adjust the height and width values “Empty Latent Image” node to change the size of the output image. Start with 512x512 if your GPU doesn’t have much memory. If you have 12 GB of VRAM (or more) you should be able to produce 1024x1024 images without any issue, however. You can also change the batch size to produce more than one variant of each prompt when you initiate image generation.
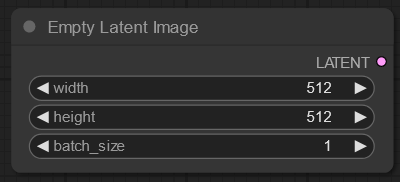
Now you’re done. Click “Queue Prompt” to initiate image generation. You will see each node light up while it is active.
Here is one of the images we got:

ComfyUI is powerful, and extremely flexible. If you want to perform additional operations on an image, just right-click and start adding nodes.
You can add as many model and modification nodes as you want, but keep in mind that every step in the process, every node you add, will increase computational time. The Stable Diffusion community has created a huge number of pre-built node arrangements (called workflows, usually) that allow you to fine-tune your results. We’ve tested a few and found they can often significantly improve your results. As always, be cautious downloading and using community resources — the Stable Diffusion community is fairly safe, but you can never be too careful.
How to Fix the “CUDA Out Of Memory” Error in AUTOMATIC1111’s WebUI
The bigger the image you make, the more video memory is required. The first thing you should try is generating smaller images. Stable Diffusion produces good — albeit very different — images at 256x256.
If you’re itching to make larger images on a computer that doesn’t have issues with 512x512 images, or you’re running into various “Out of Memory” errors, there are some changes to the configuration that should help.
Open up “webui-user.bat” in Notepad , or any other plain text editor you want. Just right-click “webui-user.bat,” click “Edit,” and then select Notepad. Identify the line that reads set COMMANDLINE_ARGS=. That is where you’re going to place the commands to optimize how Stable Diffusion runs.
Related: How to Write a Batch Script on Windows
If you just want to make huge pictures, or you’re running out of RAM on a GTX 10XX series GPU, try out --opt-split-attention first. It’ll look like this:
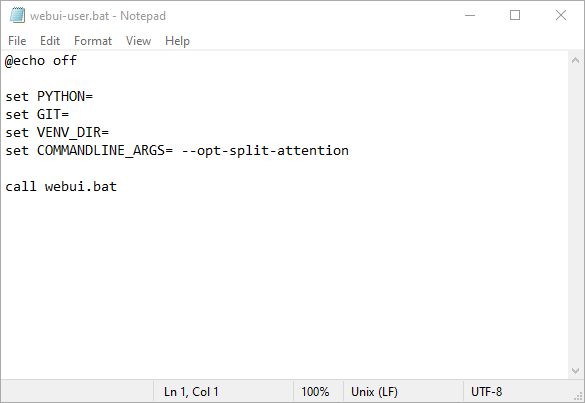
Then click File > Save. Alternatively, you can hit Ctrl+S on your keyboard.
If you’re still getting memory errors, try adding --medvram to the list of command line arguments (COMMANDLINE_ARGS).

You can add --always-batch-cond-uncond to try and fix additional memory issues if the previous commands didn’t help. There is also an alternative to --medvram that might reduce VRAM usage even more, --lowvram, but we can’t attest to whether or not it’ll actually work.
The addition of a user interface is a critical step forward in making these sorts of AI-driven tools accessible to everyone. The possibilities are nearly endless, and even a quick glance at the online communities dedicated to AI art will show you just how powerful the technology is, even while in its infancy. Of course, if you don’t have a gaming computer, or you don’t want to worry about the setup, you can always useone of the online AI art generators . Just keep in mind that you cannot assume your entries are private.
Also read:
- [New] 2024 Approved Auditory Storytelling in Cinematic Openings
- [New] Top Editors' Secret Best FREE Premiere Pro Resources
- [Updated] 2024 Approved How to Layer Melodies Into Instagram Media Content
- [Updated] Unlocking the Full Potential of ZOOM & FB Live Broadcasts
- [Updated] Unveiling Top Templates for TikTok Videos
- 2024 Approved Proven Strategies for Unveiling Pure Photospace Using Photopea
- 2024 Approved The Troubleshooting Companion Restoring SRT Functionality in Premiere
- 2024 Approved Transforming Audio to Text on Slides for PPT
- Aerial Mastery with Husqvarna H501X4 FPV Analysis for 2024
- Incorporating iTunes Vibes Into Videos for 2024
- Mini-Media Magic Which Social Site Captures the Crowd Faster for 2024 YouTubes or TikToks?
- Resolving the Problem of Windows 7 Update Download Failures
- Smooth Gaming Experience Awaits: Overcome Startup Glitches in Hogwarts Legacy with 8 Key Tips
- Ultimate Picture Sequence Architect
- Unleash Creative Energy Video Creation Tips on the Latest Windows 10 Edition for 2024
- Unlock Full Screen Potential on YouTube Videos
- Unlock Your Film's Potential Top 11 Color Grading and Correction Methods for 2024
- Title: 1. Guide: Installing and Using Local Stable Diffusion with Graphical Interface on Windows
- Author: Mark
- Created at : 2024-12-28 16:10:22
- Updated at : 2025-01-02 17:09:20
- Link: https://some-guidance.techidaily.com/1-guide-installing-and-using-local-stable-diffusion-with-graphical-interface-on-windows/
- License: This work is licensed under CC BY-NC-SA 4.0.